For technical PMs and product-focused founders
From feedback→prioritized decisions→production PRs.
"Users taking 4s to load results page..."
Connects with your stack
Why BuildRight is different
Deterministic Signals (not vibes)
Hard metrics like velocity and customer count. No arbitrary scores.
Evidence Trail
Every spec and PR links directly to real customer quotes.
Closed Loop Execution
Opens style-matched GitHub PRs on your repo. Not just documents.
Prioritization that doesn't guess.
BuildRight computes deterministic, actionable metrics straight from your raw feedback. No abstract scoring or hallucinations.
Hard Signals
Customer count, spread, and recency of mentions.
Velocity
Is this problem accelerating, steady, or cooling off?
Projected Impact
What happens if we fix this? (Midpoint reduction).
How it works
Five steps. Zero tickets.
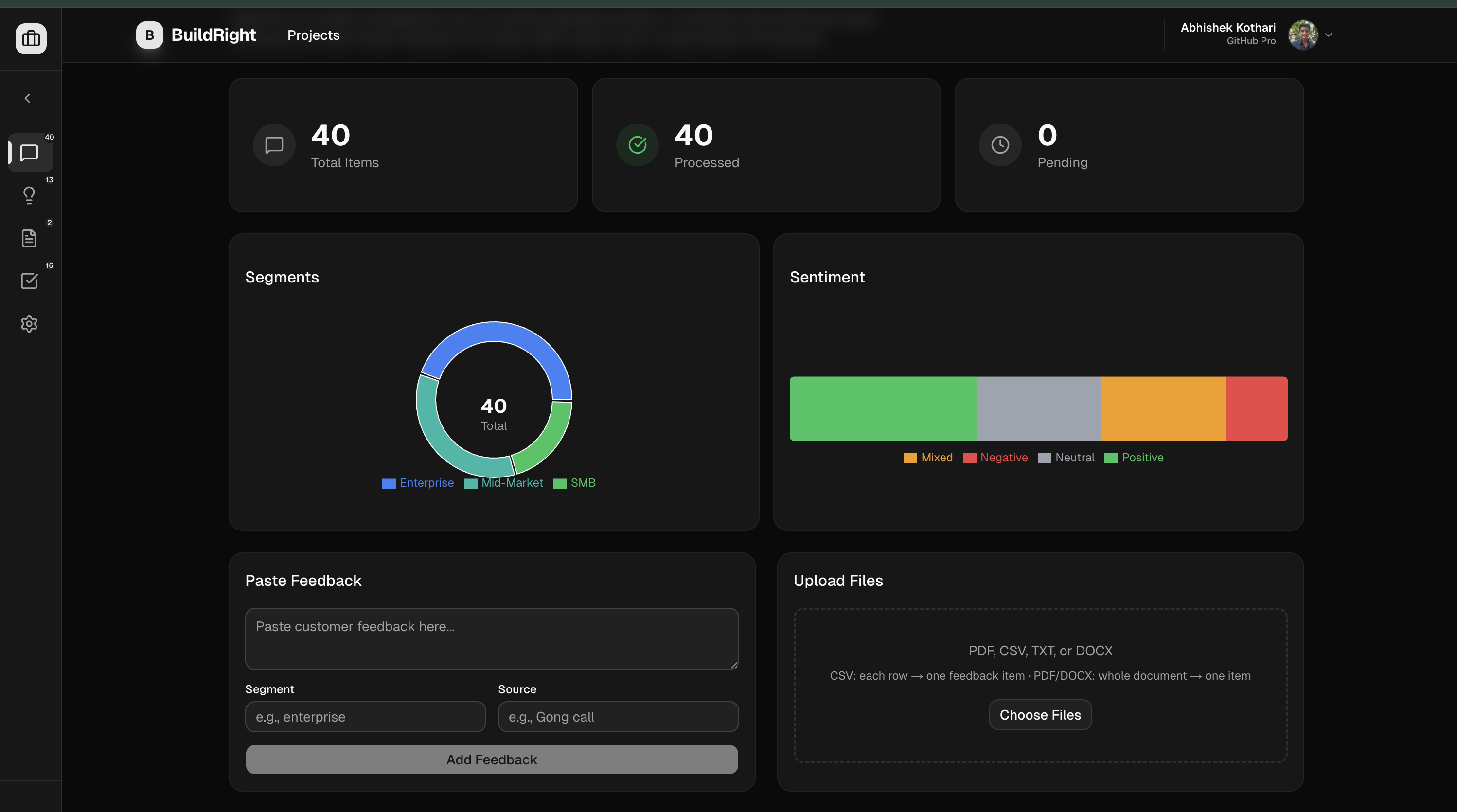
Ingest raw customer feedback directly from support tickets, interviews, and NPS responses. BuildRight reads it all.
Every decision, on record.
AI shouldn't operate in a black box. BuildRight links every PR back to the exact customer signal that inspired it.
Cryptographic Traceability
Every pull request is automatically tagged with the primary customer quotes and source IDs that defined the scope.
Confidence Propagation
Agents score data density at every layer. Features built on weak signals are flagged for manual review before implementation.
Total Alignment
Your entire organization finally knows what shipped, why, and exactly which customers are getting what they asked for.
Anti-Hallucination Gate
What happens if confidence is low? Agents flag weak signals (e.g., coverage too narrow). These never rank high and require manual PM approval before turning into specs.
Evidence: 1 casual mention
Evidence: 14 urgent quotes
Customer Quote
"The export flow is broken for large datasets."
Synthesized Theme
Export reliability · 14 mentions · High impact
Generated Spec
Problem · Acceptance criteria · Scope defined
Engineering Task
Fix CSV chunking for exports > 10k rows
GitHub PR
PR #482 opened · Evidence trail attached
Every node in this trail links directly to the original customer quote.
Built for engineering teams.
Reads your rules. Obeys your architecture.
BuildRight aggressively indexes your repository before writing code. It natively understands your custom UI tokens, linting rules, schema dependencies, and internal blocklists.
Use the <ErrorBoundary> wrapper here instead of a raw try/catch block.
8f2b3e4Refactor to use ErrorBoundary wrapperIterates with you in the PR.
It doesn't just throw code over the wall. Leave a standard GitHub comment to request structural changes, and the agent processes the feedback, tests it, and pushes a fix commit in seconds.
Token-optimized architecture.
BuildRight isolates your custom Style Guides and strategically chunks repository context to achieve extreme token-efficiency. Authoring a full feature branch costs a fraction of standard API-wrapper scaling.
Context Caching Enabled
Not another AI wrapper.
Most tools stop at insights. BuildRight closes the loop, turning raw feedback into shipped, reviewed code with a traceable paper trail at every step.
BuildRight (Complete Pipeline)
Generic AI tools (e.g. ChatGPT, Notion AI)
Traditional PM tools (e.g. Jira + manual spec)
Other tools stop at spec or ticket. BuildRight opens the PR.
Starting from zero?
Let us build the foundation.
BuildRight isn't just for fixing bugs. Using our Discovery Flow, you can upload raw market research, interview transcripts, or just a rough idea, and our autonomous AI pipeline takes it from there.
Find the exact quotes you need.
BuildRight automatically scours your messy data to identify market gaps and validate your core hypothesis before a single line of code is written.
Scaffold the repository instantly.
Once validated, BuildRight provisions a greenfield GitHub repository, generates the foundational project architecture, and pushes the day-one pull request.
Total Data Privacy.
Your telemetry remains your telemetry. BuildRight operates under standard enterprise data retention policies to ensure complete intellectual property isolation.
Zero Training Retention
Your feedback is processed by Claude via encrypted APIs. Anthropic prohibits using API payloads for model training.
Encrypted Transit & Storage
All data rests in fully encrypted PostgreSQL databases, natively secured with TLS in transit at every hop.
Strict Account Scoping
Row-level security ensures your insights and metrics are totally invisible outside your explicitly authenticated context.
Permanent Deprovisioning
You maintain sovereign control. You can permanently annihilate all traces of your projects at any time.
Ready to close the loop?
Free while we're in early access.
Every decision is traceable. Every output is explainable.